Neural Networks in Feedback Control Systems
F.L. Lewis and S.S. Ge
Table of Contents
- Introduction
- Controllers’ algorithms
- Feedback Linearization Design of NN Tracking Controllers
- NN Control for Discrete-Time Systems
- Multi-loop Neural Network Feedback Control Structures
- Feedforward Control Structures for Actuator Compensation
- Neural Network Observers for Output-Feedback Control
- Reinforcement Learning Control Using NN
- Optimal Control Using NN
- Approximate Dynamic Programming and Adaptive Critics
Introduction
The aricle provides an historical overview of development of NN usage in feedback control systems and multiloop controllers algorithms using NN.
In adaptive control there are two main Neural Network Control Topologies: direct and inderect. Indirect control aims to learn dynamics of the unknown plant (dynamical system) via identifier block first; then it uses aquired information to control the plant via controller block. Direct control directly tunes the parameters of an adjustable NN controller.
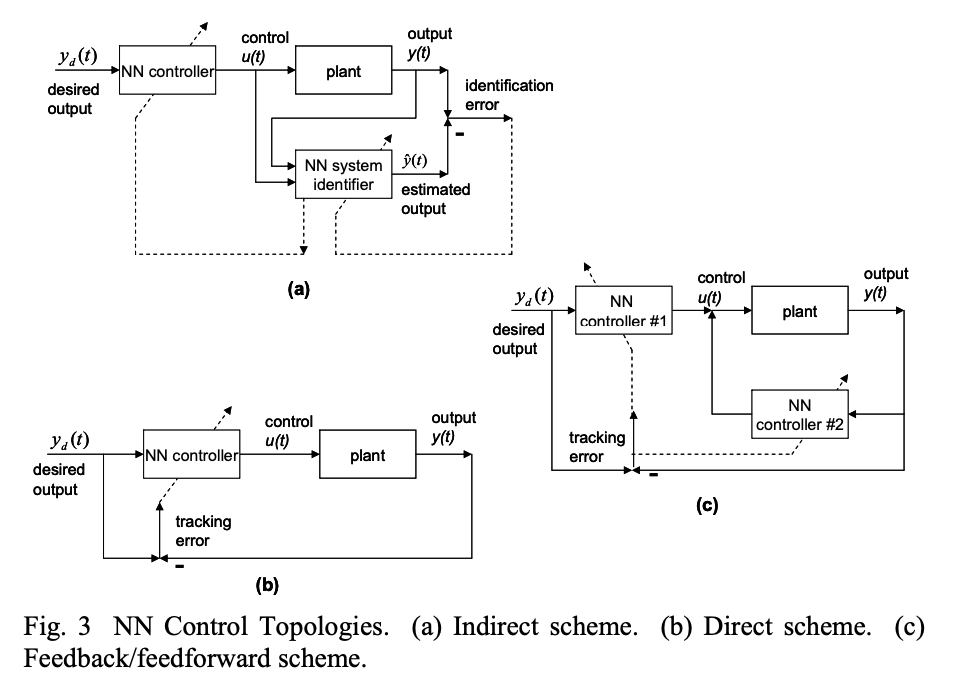 solid lines denote signal flow, dashed line - tuning.
solid lines denote signal flow, dashed line - tuning.
The challenge in using NN for feedback control is to select a adequate control system structure, and then to tune the NN weights to guarantee closed-loop stability and performance.
The use of neural networks (NN) in feedback control systems was first proposed by Werbos [1989]. Early works aimed to adress several challenges for closed-loop controll systems. The main are: “weight initialization for feedback stability, determining the gradients needed for backpropagation tuning, determining what to backpropagate, obviating the need for preliminary off-line tuning, modifying backprop so that it tunes the weights forward through time”. Overviews of the early works regarding NN control could be found in the Handbook of Intelligent Control [White 1992].
Controllers’ algorithms
Feedback Linearization Design of NN Tracking Controllers
The section dedicated to NN feedback controllers that makes a robotic system to follow a certain trajectory or path in conditions where nor the dynamics of the robot, nor disturbances are known.
Multi-Layer Neural Network Controller
It’s assumed that desired controller function and appropriate weights are unknown. The NN design approach allows for nonlinearity in the parameters, and in effect the NN learns its own basis set on-line to approximate the unknown function f(x). The structure consists of two loops: the feedback linearization loop which incorparates the NN which learns the unknown dynamics on-line to cancel the nonlinearities of the system. The outer PD tracking loop controlls behavior with specally predifined robustifying function. Tthe stability of the algorithm is proven using nonlinear stability theory (an extension of Lyapunov’s theorem).
Single-layer Neural Network Controller
If the first layer weights V are fixed so that one has the simplified tuning algorithm for the output-layer weights update.
Feedback Linearization of Nonlinear Systems Using NN
Feedback Linearization NN controller input has two parts: a feedback linearization part and plus an extra robustifying part. Then two separate NNs are trained. For the first one the weight update is exactly the same as in the Multi-Layer Neural Network Controller. To train the second NN the formula should be modified in a way that makes it’s output bounded away from zero. Otherwise the whole control would be infinite.
Partitioned Neural Networks and Input Preprocessing
This approach implies partitioning of the controller in terms of partitioned NN or neural subnets. This simplifies the design, gives added controller structure, and allows faster weight tuning algorithms. An advantage of this structured NN is that if some terms in the robot dynamics are well-known (e.g. inertia matrix M(q) and gravity G(q)), then their NNs can be replaced by equations that explicitly compute these terms.
NN Control for Discrete-Time Systems
To implement a controller algorythm on a computer it is necessary to specify it in a digital(discrete-time) form. In 1999 Lewis, Jagannathan, and Yesildirek showed that it is possible to guarantee system stability and robustness with an N-layer NN controller. Sich a controller should be composed of two parts: the gradient algorithm and robystifying descrete-time term(a.k.a. “forgetting term”).
Multi-loop Neural Network Feedback Control Structures
The class of controllers with include additional inner feedback loops is required for systems with additional dynamical complications or additional performance requirements. using Lyapunov energy-based techniques, it was shown that if each loop is bounded (state-strict passive1), then the overall multiloop NN controller provides stability, performance, and bounded NN weights (Lewis, Jagannathan, and Yesildirek, 1999). There are sevral examples of Multi-loop NN controllers provided in the article : Backstepping Neurocontroller for Electrically Driven Robot; Compensation of Flexible Modes and High-Frequency Dynamics and a Force Control algorithm. ______________________ 1 a _passive system is a system, which cannot store more energy, than energy supplied to the system. A strictly passive system bounded further by some parameter,lower than amout of input energy. For more information about passivity in control systems consult these papers: http://www.l2s.centralesupelec.fr/sites/l2s.centralesupelec.fr/files/users/loria/teaching/passivity-in-control-systems.pdf , https://www.hindawi.com/journals/mpe/2015/591854/ ._ _________________________
Feedforward Control Structures for Actuator Compensation
Since these actuator nonlinearities appear in the feedforward loop, the NN compensator must also appear in the feedforward loop
Feedforward Neurocontroller for Systems with Unknown Deadzone
The deadzone is a state when the control signal takes on small values or passes through zero. ,( since only values greater than a certain threshold can influence the system.)
Dynamic Inversion Neurocontroller for Systems with Backlash.
Blacklash - situation, when the control signal reverses in value.
Neural Network Observers for Output-Feedback Control
The idea of this control scheme comes from an observer concept in control system theory. This type of NN controllers could be used when only not all internal system information is measurable (which is almost always a case in industry) and available for a feedback. In this case an additional dynamic NN is used. This additional NN meant to provide estimates of the unmeasurable plant states.
Reinforcement Learning Control Using NN
First proposed by Mendel in 1970. Since then were rigously studied and developed. Implemintation of reinforcement learning in the control system theory frame struggles with variety of difficulties due to reduced information and therefore complications in prooving it’s stability.
Neural Network Reinforcement Learning Controller
Initially, action generating NN takes as input the desired trajectory as the user input. Then, after a plant performs an action, resulting in
the instanteous utility - r(t) - is calculated. Then the signum2 function of the r(t) is taken to critique the perfomance of the system.
, where
.
Afterwards the NN weights are tuned using only R(t) with
This tuning algorithm’s stability and tracking of closed-loop system is proven with Lyapunov energy fynction.
2The signum function is the derivative of the absolute value function (up to the indeterminacy at zero): . At zero the function is equals zero, which is useful for reinforcment learning: zero considered as a reward, where as other values as a punishment.
________
Adaptive Reinforcement Learning Using Fuzzy Logic Critic
This algorithm uses fuzzy logic system as a critic and a NN as an action generator, which controls the system. The critic system can be initialized via linguistic or heuristic notions by the user, and later on ine can interpret which information was stored by the system during the learning process.
The adaptive Critic unit output has the form of an input x parced to the Action generating NN.
, where W is an output values and q is a set of fuzzy logic basis functions. The basis functions are membership functions, and ususally represented by triangle functions. Instead of them, splines, 2nd and 3rd degree polynomials, and the RBF functions could be used.
Optimal Control Using NN
Neural Network H-2 Control Using the Hamilton-Jacobi-Bellman Equation
Neural Network H-Infinity Control Using the Hamilton-Jacobi-Isaacs Equation
Approximate Dynamic Programming and Adaptive Critics
The goal of ADP is to evaluate the optimal value and optimal control using techniques that progress forward in time. There are several techniques wich can be used:
- Heuristic Dynamic Programming (HDP): has both action generating and critic NNs with tunable parameters.
- Dual Heuristic Programming (DHP): additionaly to optimal value approximation, pedicts it’s gradient via an NN
- Q-Learning or Action Dependent HDP: uses Q function.